
Hugging Face recently introduced Falcon 180B, the largest open source Large Language Model that is said to perform as well as Google’s state of the art AI, Palm 2. And it also has no guardrails to keep it from creating unsafe of harmful outputs.
Falcon 180B Achieves State Of The Art Performance
The phrase “state of the art” means that something is performing at the highest possible level, equal to or surpassing the current example of what’s best.
It’s a big deal when researchers announce that an algorithm or large language model achieves state of the art performance.
And that’s exactly what Hugging Face says about Falcon 180B.
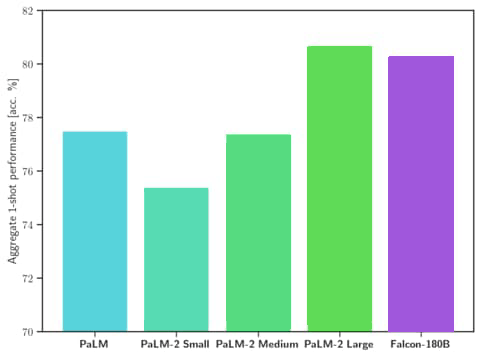
Falcon 180B achieves state of the art performance on natural language tasks, beats out previous open source models and also “rivals” Google’s Palm 2 in performance.
Those aren’t just boasts, either.
Hugging Face’s claim that Falcon 180B rivals Palm 2 is backed up by data.
The data shows that Falcon 180B outperforms the previous most powerful open source model Llama 270B across a range of tasks used to measure how powerful an AI model is.
Falcon 180B even outperforms OpenAI’s GPT-3.5.
The testing data also shows that Falcon 180B performs at the same level as Google’s Palm 2.
Screenshot of Performance Comparison
The announcement explained:
“Falcon 180B is the best openly released LLM today, outperforming Llama 2 70B and OpenAI’s GPT-3.5…
Falcon 180B typically sits somewhere between GPT 3.5 and GPT4 depending on the evaluation benchmark…”
The announcement goes on to imply that additional fine tuning of the model by users may improve the performance even higher.
Minor technical issues that muddy up indexing, like triggering 301 redirects by internal links to old URLs that have been updated with a category structure.
Dataset Used To Train Falcon 180B
Hugging Face released a research paper (PDF version here) containing details of the dataset used to train Falcon 180B.
It’s called The RefinedWeb Dataset.
This dataset consists only of content from the Internet, obtained from the open source Common Crawl, a publicly available dataset of the web.
The dataset is subsequently filtered and put through a process of deduplication (the removal of duplicate or redundant data) to improve the quality of what’s left.
What the researchers are trying to achieve with the filtering is to remove machine-generated spam, content that is repeated, boilerplate, plagiarized content and data that isn’t representative of natural language.
The research paper explains:
“Due to crawling errors and low quality sources, many documents contain repeated sequences: this may cause pathological behavior in the final model…
…A significant fraction of pages are machine-generated spam, made predominantly of lists of keywords, boilerplate text, or sequences of special characters.
Such documents are not suitable for language modeling…
…We adopt an aggressive deduplication strategy, combining both fuzzy document matches and exact sequences removal.”
Apparently it becomes imperative to filter and otherwise clean up the dataset because it’s exclusively comprised of web data, as opposed to other datasets that add non-web data.
The researchers efforts to filter out the nonsense resulted in a dataset that they claim is every bit as good as more curated datasets that are made up of pirated books and other sources of non-web data.
They conclude by stating that their dataset is a success:
“We have demonstrated that stringent filtering and deduplication could result in a five trillion tokens web only dataset suitable to produce models competitive with the state-of-the-art, even outperforming LLMs trained on curated corpora.”
Falcon 180B Has Zero Guardrails
Notable about Falcon 180B is that no alignment tuning has been done to keep it from generating harmful or unsafe output and nothing to prevent it from inventing facts and outright lying.
As a consequence, the model can be tuned to generate the kind of output that can’t be generated with products from OpenAI and Google.
This is listed in a section of the announcement titled limitations.
Hugging Face advises:
“Limitations: the model can and will produce factually incorrect information, hallucinating facts and actions.
As it has not undergone any advanced tuning/alignment, it can produce problematic outputs, especially if prompted to do so.”
Commercial Use Of Falcon 180B
Hugging Face allows commercial use of Falcon 180B.
However it’s released under a restrictive license.
Those who wish to use Falcon 180B are encouraged by Hugging Face to first consult a lawyer.
Falcon 180B Is Like A Starting Point
Lastly, the model hasn’t undergone instruction training, which means that it has to be trained to be an AI chatbot.
So it’s like a base model that needs more to become whatever users want it to be. Hugging Face also released a chat model but it’s apparently a “simple” one.
Hugging Face explains:
“The base model has no prompt format. Remember that it’s not a conversational model or trained with instructions, so don’t expect it to generate conversational responses—the pretrained model is a great platform for further finetuning, but you probably shouldn’t directly use it out of the box.
The Chat model has a very simple conversation structure.”
Read the official announcement:
Spread Your Wings: Falcon 180B is here
Featured image by Shutterstock/Giu Studios