
Google’s Bard is based on the LaMDA language model, trained on datasets based on Internet content called Infiniset of which very little is known about where the data came from and how they got it.
The 2022 LaMDA research paper lists percentages of different kinds of data used to train LaMDA, but only 12.5% comes from a public dataset of crawled content from the web and another 12.5% comes from Wikipedia.
Google is purposely vague about where the rest of the scraped data comes from but there are hints of what sites are in those datasets.
Google’s Infiniset Dataset
Google Bard is based on a language model called LaMDA, which is an acronym for Language Model for Dialogue Applications.
LaMDA was trained on a dataset called Infiniset.
Infiniset is a blend of Internet content that was deliberately chosen to enhance the model’s ability to engage in dialogue.
The LaMDA research paper (PDF) explains why they chose this composition of content:
“…this composition was chosen to achieve a more robust performance on dialog tasks …while still keeping its ability to perform other tasks like code generation.
As future work, we can study how the choice of this composition may affect the quality of some of the other NLP tasks performed by the model.”
The research paper makes reference to dialog and dialogs, which is the spelling of the words used in this context, within the realm of computer science.
In total, LaMDA was pre-trained on 1.56 trillion words of “public dialog data and web text.”
The dataset is comprised of the following mix:
- 12.5% C4-based data
- 12.5% English language Wikipedia
- 12.5% code documents from programming Q&A websites, tutorials, and others
- 6.25% English web documents
- 6.25% Non-English web documents
- 50% dialogs data from public forums
The first two parts of Infiniset (C4 and Wikipedia) is comprised of data that is known.
The C4 dataset, which will be explored shortly, is a specially filtered version of the Common Crawl dataset.
Only 25% of the data is from a named source (the C4 dataset and Wikipedia).
The rest of the data that makes up the bulk of the Infiniset dataset, 75%, consists of words that were scraped from the Internet.
The research paper doesn’t say how the data was obtained from websites, what websites it was obtained from or any other details about the scraped content.
Google only uses generalized descriptions like “Non-English web documents.”
The word “murky” means when something is not explained and is mostly concealed.
Murky is the best word for describing the 75% of data that Google used for training LaMDA.
There are some clues that may give a general idea of what sites are contained within the 75% of web content, but we can’t know for certain.
C4 Dataset
C4 is a dataset developed by Google in 2020. C4 stands for “Colossal Clean Crawled Corpus.”
This dataset is based on the Common Crawl data, which is an open-source dataset.
About Common Crawl
Common Crawl is a registered non-profit organization that crawls the Internet on a monthly basis to create free datasets that anyone can use.
The Common Crawl organization is currently run by people who have worked for the Wikimedia Foundation, former Googlers, a founder of Blekko, and count as advisors people like Peter Norvig, Director of Research at Google and Danny Sullivan (also of Google).
How C4 is Developed From Common Crawl
The raw Common Crawl data is cleaned up by removing things like thin content, obscene words, lorem ipsum, navigational menus, deduplication, etc. in order to limit the dataset to the main content.
The point of filtering out unnecessary data was to remove gibberish and retain examples of natural English.
This is what the researchers who created C4 wrote:
“To assemble our base data set, we downloaded the web extracted text from April 2019 and applied the aforementioned filtering.
This produces a collection of text that is not only orders of magnitude larger than most data sets used for pre-training (about 750 GB) but also comprises reasonably clean and natural English text.
We dub this data set the “Colossal Clean Crawled Corpus” (or C4 for short) and release it as part of TensorFlow Datasets…”
There are other unfiltered versions of C4 as well.
The research paper that describes the C4 dataset is titled, Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer (PDF).
Another research paper from 2021, (Documenting Large Webtext Corpora: A Case Study on the Colossal Clean Crawled Corpus – PDF) examined the make-up of the sites included in the C4 dataset.
Interestingly, the second research paper discovered anomalies in the original C4 dataset that resulted in the removal of webpages that were Hispanic and African American aligned.
Hispanic aligned webpages were removed by the blocklist filter (swear words, etc.) at the rate of 32% of pages.
African American aligned webpages were removed at the rate of 42%.
Presumably those shortcomings have been addressed…
Another finding was that 51.3% of the C4 dataset consisted of webpages that were hosted in the United States.
Lastly, the 2021 analysis of the original C4 dataset acknowledges that the dataset represents just a fraction of the total Internet.
The analysis states:
“Our analysis shows that while this dataset represents a significant fraction of a scrape of the public internet, it is by no means representative of English-speaking world, and it spans a wide range of years.
When building a dataset from a scrape of the web, reporting the domains the text is scraped from is integral to understanding the dataset; the data collection process can lead to a significantly different distribution of internet domains than one would expect.”
The following statistics about the C4 dataset are from the second research paper that is linked above.
The top 25 websites (by number of tokens) in C4 are:
- patents.google.com
- en.wikipedia.org
- en.m.wikipedia.org
- www.nytimes.com
- www.latimes.com
- www.theguardian.com
- journals.plos.org
- www.forbes.com
- www.huffpost.com
- patents.com
- www.scribd.com
- www.washingtonpost.com
- www.fool.com
- ipfs.io
- www.frontiersin.org
- www.businessinsider.com
- www.chicagotribune.com
- www.booking.com
- www.theatlantic.com
- link.springer.com
- www.aljazeera.com
- www.kickstarter.com
- caselaw.findlaw.com
- www.ncbi.nlm.nih.gov
- www.npr.org
These are the top 25 represented top level domains in the C4 dataset:
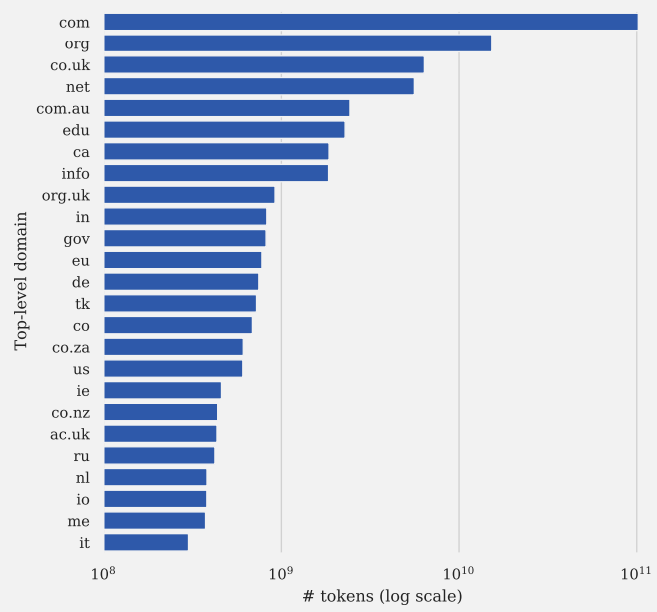 Screenshot from Documenting Large Webtext Corpora: A Case Study on the Colossal Clean Crawled Corpus
Screenshot from Documenting Large Webtext Corpora: A Case Study on the Colossal Clean Crawled CorpusIf you’re interested in learning more about the C4 dataset, I recommend reading Documenting Large Webtext Corpora: A Case Study on the Colossal Clean Crawled Corpus (PDF) as well as the original 2020 research paper (PDF) for which C4 was created.
What Could Dialogs Data from Public Forums Be?
50% of the training data comes from “dialogs data from public forums.”
That’s all that Google’s LaMDA research paper says about this training data.
If one were to guess, Reddit and other top communities like StackOverflow are safe bets.
Reddit is used in many important datasets such as ones developed by OpenAI called WebText2 (PDF), an open-source approximation of WebText2 called OpenWebText2 and Google’s own WebText-like (PDF) dataset from 2020.
Google also published details of another dataset of public dialog sites a month before the publication of the LaMDA paper.
This dataset that contains public dialog sites is called MassiveWeb.
We’re not speculating that the MassiveWeb dataset was used to train LaMDA.
But it contains a good example of what Google chose for another language model that focused on dialogue.
MassiveWeb was created by DeepMind, which is owned by Google.
It was designed for use by a large language model called Gopher (link to PDF of research paper).
MassiveWeb uses dialog web sources that go beyond Reddit in order to avoid creating a bias toward Reddit-influenced data.
It still uses Reddit. But it also contains data scraped from many other sites.
Public dialog sites included in MassiveWeb are:
- Quora
- YouTube
- Medium
- StackOverflow
Again, this isn’t suggesting that LaMDA was trained with the above sites.
It’s just meant to show what Google could have used, by showing a dataset Google was working on around the same time as LaMDA, one that contains forum-type sites.
The Remaining 37.5%
The last group of data sources are:
- 12.5% code documents from sites related to programming like Q&A sites, tutorials, etc;
- 12.5% Wikipedia (English)
- 6.25% English web documents
- 6.25% Non-English web documents.
Google does not specify what sites are in the Programming Q&A Sites category that makes up 12.5% of the dataset that LaMDA trained on.
So we can only speculate.
Stack Overflow and Reddit seem like obvious choices, especially since they were included in the MassiveWeb dataset.
What “tutorials” sites were crawled? We can only speculate what those “tutorials” sites may be.
That leaves the final three categories of content, two of which are exceedingly vague.
English language Wikipedia needs no discussion, we all know Wikipedia.
But the following two are not explained:
English and non-English language web pages are a general description of 13% of the sites included in the database.
That’s all the information Google gives about this part of the training data.
Should Google Be Transparent About Datasets Used for Bard?
Some publishers feel uncomfortable that their sites are used to train AI systems because, in their opinion, those systems could in the future make their websites obsolete and disappear.
Whether that’s true or not remains to be seen, but it is a genuine concern expressed by publishers and members of the search marketing community.
Google is frustratingly vague about the websites used to train LaMDA as well as what technology was used to scrape the websites for data.
As was seen in the analysis of the C4 dataset, the methodology of choosing which website content to use for training large language models can affect the quality of the language model by excluding certain populations.
Should Google be more transparent about what sites are used to train their AI or at least publish an easy to find transparency report about the data that was used?
Featured image by Shutterstock/Asier Romero